DERAIL: Diagnostic Environments for Reward And Imitation Learning.
Freire, Pedro, et al. “DERAIL: Diagnostic Environments for Reward And Imitation Learning.” arXiv preprint arXiv:2012.01365 (2020).
Reward and imitation learning offer promise for tackling the value alignment problem in AI: How do we create agents that do what we want, not what we say? In #PaperReadingGroup006, we looked at Deep Reinforcement Learning from Human Preferences (DRLHP), an RL algorithm that doesn’t receive direct reward signals from the environment but learns a reward estimate from human feedback. Following that, I have been trying to catch up with the rest of the ideas within the value learning space.
For this week’s reading, I had a hard time deciding between over two decades’ worth of value learning literature, but it turns out that this paper, while not one of the classics, turned out to be the most comfortable jumping in point for me.
This work comes from Stuart Russell’s group at Berkeley - the Center for Human-Compatible Artificial Intelligence (CHAI) - which has been a large contributor to this field, particularly in Cooperative Inverse Reinforcement Learning (CIRL) techniques. Being a recent benchmarks paper, this gives a good lay of the land showing which LfH algorithms are relevant in 2020 along with a taxonomy of common difficulties.
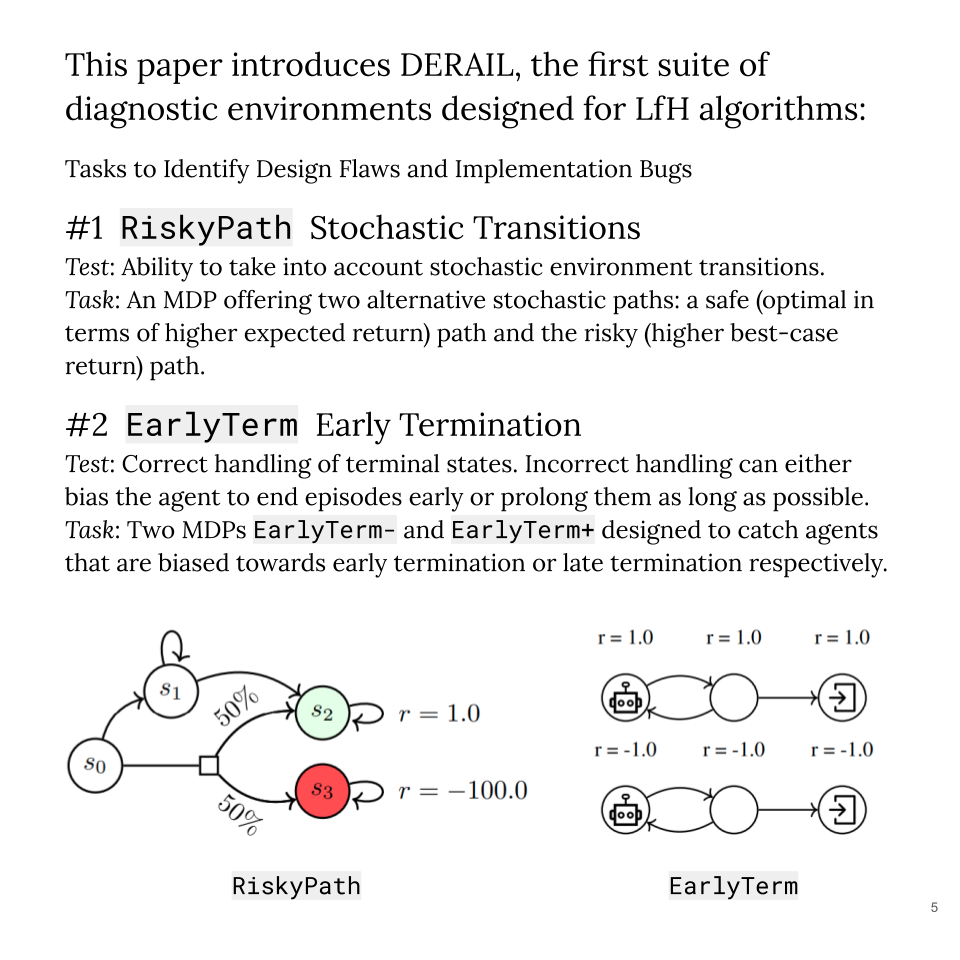
It occurred to me that the DERAIL suite should also be useful for general RL development since none of the evaluated capabilities is unique to LfH algorithms. But looking at the near-perfect scores of PPO in their results, I guess that these toy problems are much too easy for standard RL algorithms.
In any case, it’s really great to see a benchmarks suite coming out specifically for LfH algorithms because I think often the hardest part of tackling a new problem is figuring out what the right questions are. In research, there are few questions more concrete than a well-scoped benchmark problem.
View in Google Slides.
Join the conversation on: