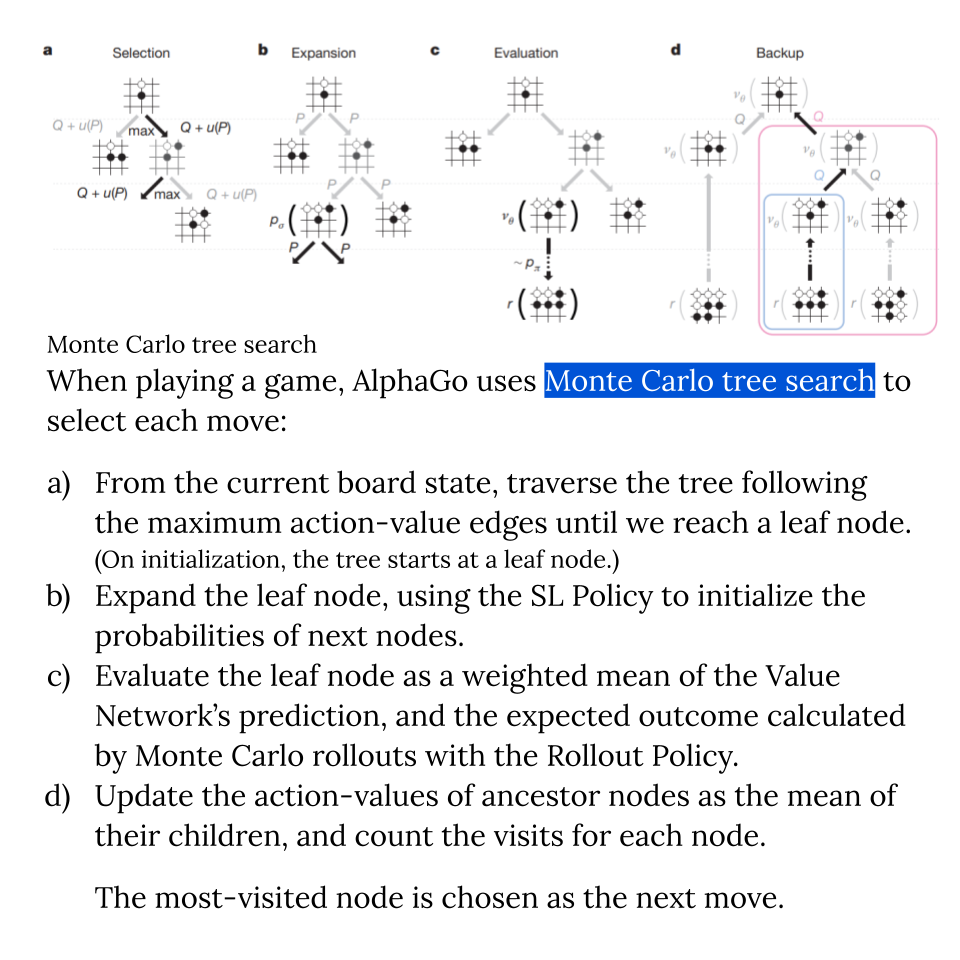
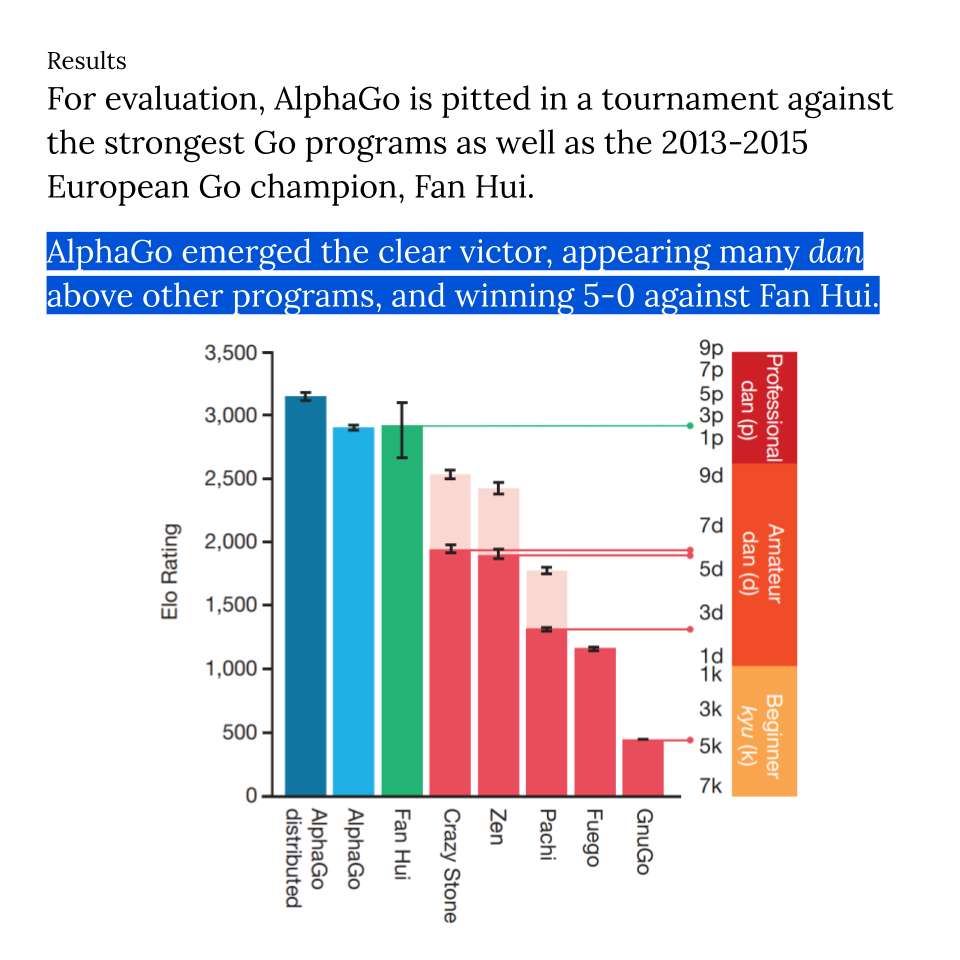
Mastering the game of Go with deep neural networks and tree search.
Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” nature 529.7587 (2016): 484-489.
Can we talk about how good the AlphaGo documentary is? It is exciting and riveting in the way that sports movies are, it is incredibly well-paced as a story, it is informative, gives a rare peek into the team and the people behind otherwise opaque technology, and clearly separates fact from fiction - unsurprisingly, being straight from the horse’s, or DeepMind’s, mouth. It really brings home the significance of the accomplishment and the questions that naturally arise. I strongly recommend it for anybody - it is not a technical movie, and it is done in a way that even your grandparents could enjoy!
Back to the paper itself. AlphaGo was the first in a rapid series of works from DeepMind which year after year broke new boundaries for complex planning tasks. After AlphaGo came AlphaGo Zero, then Alpha Zero, and lastly (for now) MuZero, which was just published last year. For this week’s paper, I had actually wanted to read about MuZero but it is a complicated beast with many references to AlphaGo/AlphaZero, so I figured I should start at the beginning to build an intuition for why MuZero turned out the way it is.
And here, in fact, is a pattern which inspires me. Often when we encounter ideas in the wild, we lack the context to understand where they come from. This results in awe as well as intimidation, for surely it takes true genius to imagine such a thing! Not discounting any respect I have for the creators, it is helpful and encouraging to understand that ideas don’t emerge from a vacuum: MuZero was the result of many years of iteration that began with AlphaGo, and AlphaGo itself is simply a well-informed combination of techniques which were already existing and popular at the time (neural networks and MCTS). And such goes the forward march of science, one step at a time!
View in Google Slides.
Join the conversation on: