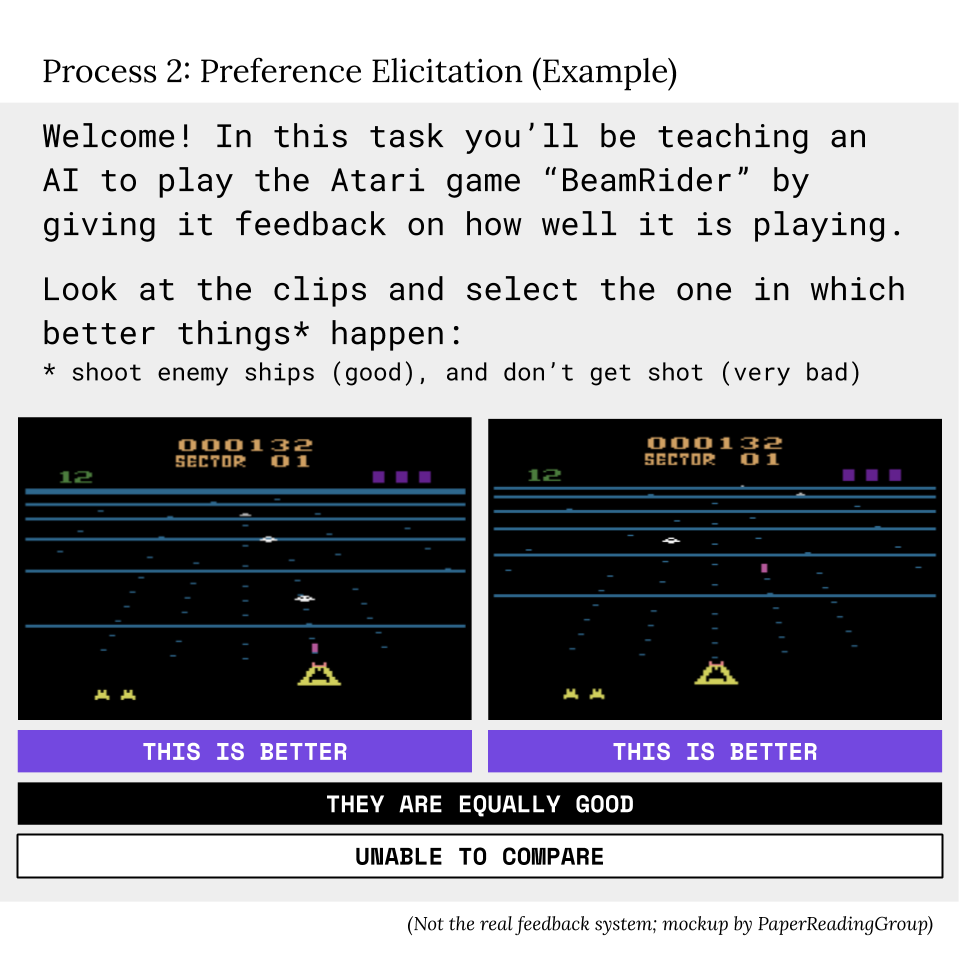
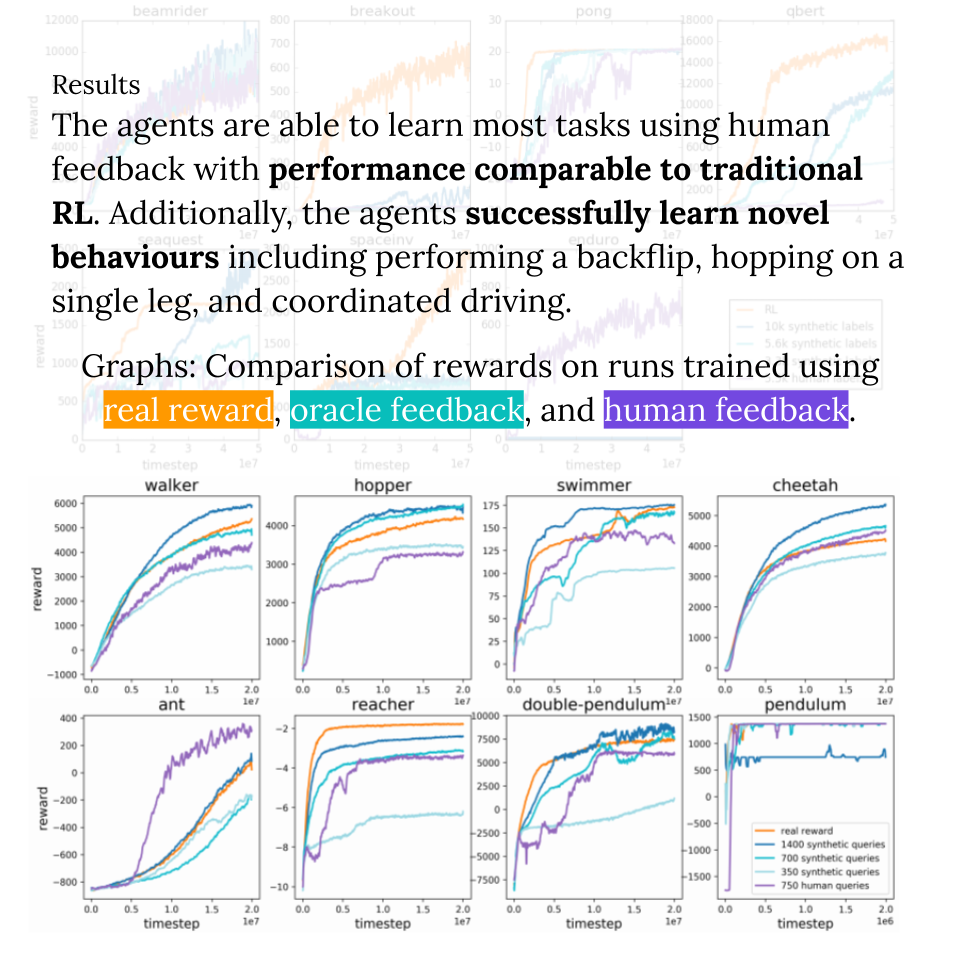
Deep reinforcement learning from human preferences.
Christiano, Paul, et al. “Deep reinforcement learning from human preferences.” arXiv preprint arXiv:1706.03741 (2017).
This one is a big deal, although it’s easy to underestimate. The first time I came across this paper I went “Ugh” and skipped it because reliance on human feedback for training seemed to me like a step backwards from the self-learning systems we dream of. It reminded me of the brute ugliness of the hundreds of human-years that have been poured into hand-labelling supervised datasets.
But as I dig further into how we can come up with goal specifications which don’t end up misaligned, I’m convinced that we will need to replace fixed rewards with rewards that self-update to maximize cooperation with humans. This system does exactly that.
That said, a thousand instances of human feedback per task still sounds like a lot. Here though, there is room for improvement: 1) These agents are learning from a blank slate. Pre-training with prior knowledge of the world should speed up incremental task learning. 2) There is no need to be put-off by the current clunkiness - early work may be driven by Mechanical Turk labour, but in the future, we can work towards feedback in much more natural forms including conversation. 3) Learning from preference feedback is not exclusive - most likely we will be able to supplement this with unsupervised learning as well as other forms of feedback (e.g. demonstration-based / inverse reinforcement learning).
Even in the near future, I can see the attractiveness of human preferences for interacting with machines. Next-gen AutoML systems would no longer need mountains of expertly curated train-label pairs - just a few hours of time by non-experts to answer preference questionnaires would suffice!
View in Google Slides.
Join the conversation on: