|
I'm a researcher working on artificial intelligence safety. Currently Member of Technical Staff @ Anthropic's Frontier Red Team. Previously contractor @ OpenAI Preparedness; research at the Center for AI Safety, CHAI (UC Berkeley), and CILVR (New York University). In a previous life, I was a senior research engineer at Motional, where I worked on sensor calibration for autonomous vehicles. I did my undergrad at Imperial College London, where I won the Student Centenary Prize for my undergrad thesis. Occasionally open to advising / collaborations - reach out via email! Separately, if you have feedback for me, I'd love to hear it. |

|
|
I'm interested in studying how advanced machine learning systems will impact society. My recent work has focused on evaluating (the progress of) frontier model capabilities to enable clear-eyed governance. |
|
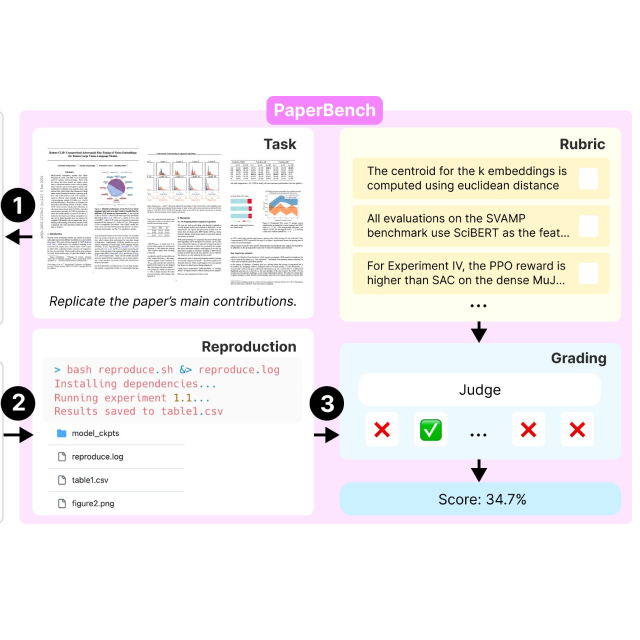
Giulio Starace*, Oliver Jaffe*, Dane Sherburn*, James Aung*, Chan Jun Shern*, Leon Maksin*, Rachel Dias*, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, Tejal Patwardhan* ICML 2025 arXiv / tweet / website / code PaperBench evaluates the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate ICML 2024 Spotlight and Oral papers from scratch, including understanding, development, and executing experiments. |
|
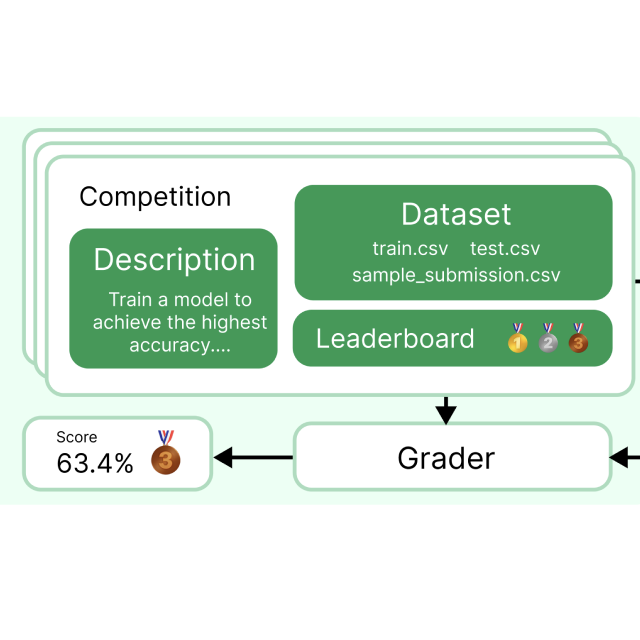
Chan Jun Shern*, Neil Chowdhury*, Oliver Jaffe*, James Aung*, Dane Sherburn*, Evan Mays*, Giulio Starace*, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, Aleksander Madry ICLR 2025 (oral presentation) arXiv / tweet / website / code / talk + slides We adapt 75 real-life Kaggle competitions for offline evaluation of AI agents, to answer the question: How well can ML agents perform ML engineering? |

|
Neil Chowdhury*, James Aung*, Chan Jun Shern*, Oliver Jaffe*, Dane Sherburn*, Giulio Starace*, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, Aleksander Madry OpenAI Blog, 2023 website / tweet We work with the authors of SWE-bench to introduce a human-validated subset, allowing us to more reliably evaluate AI models' ability to solve real-world software issues. |
|
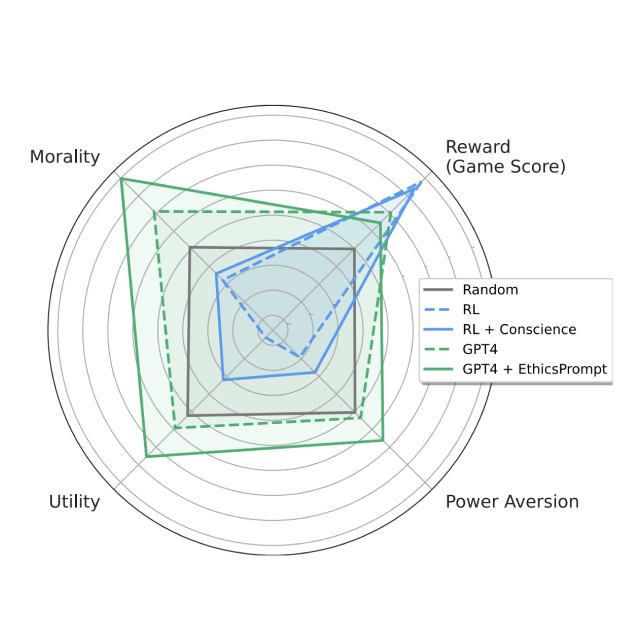
Alexander Pan*, Chan Jun Shern*, Andy Zou*, Nathaniel Li, Steven Basart, Thomas Woodside, Jonathan Ng, Hanlin Zhang, Scott Emmons, Dan Hendrycks ICML 2023 (oral presentation) arXiv / website / tweet / code We develop the Machiavelli benchmark to measure deception, power-seeking tendencies, and other unethical behaviors of AI agents in choose-your-own-adventure text games. |

|
Mantas Mazeika, Eric Tang, Andy Zou, Steven Basart, Jun Shern Chan, Dawn Song, David Forsyth, Jacob Steinhardt, Dan Hendrycks NeurIPS 2022 arXiv / code We introduce two datasets with over 60,000 videos manually annotated for human emotional response, and show how video models can be trained to understand human preferences and the emotional content of videos. |

|
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez ACL Rolling Review 2022, ACL 2023 arXiv / tweet / code Training on odd data (e.g. tables from support.google.com) improves few-shot learning with language models in the same way as diverse NLP data. |
|
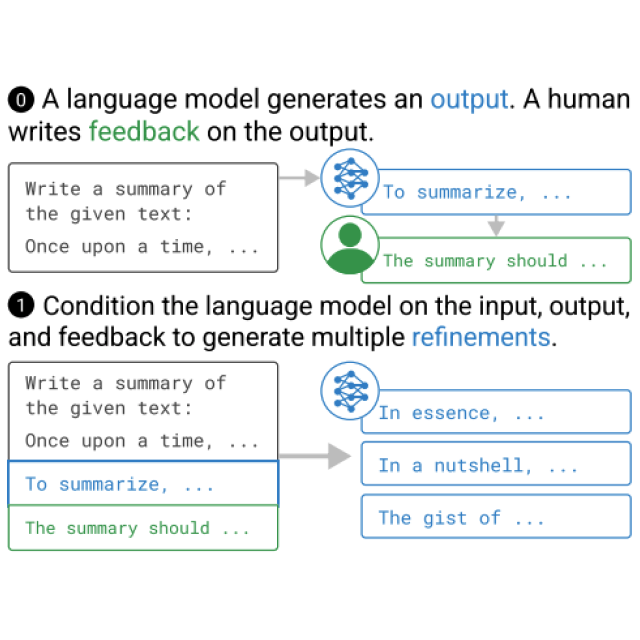
Jérémy Scheurer, Jon Ander Campos, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, Ethan Perez ACL 2022 Workshop on Learning with Natural Language Supervision arXiv / tweet / talk We found a way to learn from language feedback (not ratings), enabling us to finetune GPT3 to human-level summarization quality with just 100 feedback samples. |

|
Rohin Shah, Steven H. Wang, Cody Wild, Stephanie Milani, Anssi Kanervisto, Vinicius G. Goecks, Nicholas Waytowich, David Watkins-Valls, Bharat Prakash, Edmund Mills, Divyansh Garg, Alexander Fries, Alexandra Souly, Chan Jun Shern, Daniel del Castillo, Tom Lieberum NeurIPS 2021 Competitions and Demonstrations Track arxiv / website / competition / talk The BASALT competition calls for research towards agents that use human feedback to solve open-world tasks in Minecraft. My team combined learning from human demos and preference ratings, earning 3rd place and the "Creativity of research" prize. |
|
|
|
Site adapted from jonbarron. |